RE-dice
主要就是扔骰子游戏,要扔3-1-3-3-7
根据字符串提示找到最后会输出的flag的位置,我这里是v84,按alt+t搜索文本v84,再按ctrl+t搜索下一个
flag =v84^v87
发现v84一开始被byte_xxx赋值了,找到数据,选中全部按shift+E,初始值保存十六进制数据到文本
132138153D3357472D276A73440526595C79174445771A75497D054A78746A70420271050F220800
然后跟进到第二个对v84操作处

又要开始跟进v87了…
它也被byte_xxx赋初始值,提取数据02370F350F3C15073C302A30551237151E35015100
跟进发现v87和v86异或了

再跟进,发现v87又和v85异或了

终于就结束了
最后flag=v84^v87^v86^v85
那么我们先关注v86
我终于不用再qq截图了…
cmd+shift+4 截图,选中文件return重命名

v86被赋初值16,其他地方没有改动了
再关注v85,初值为6
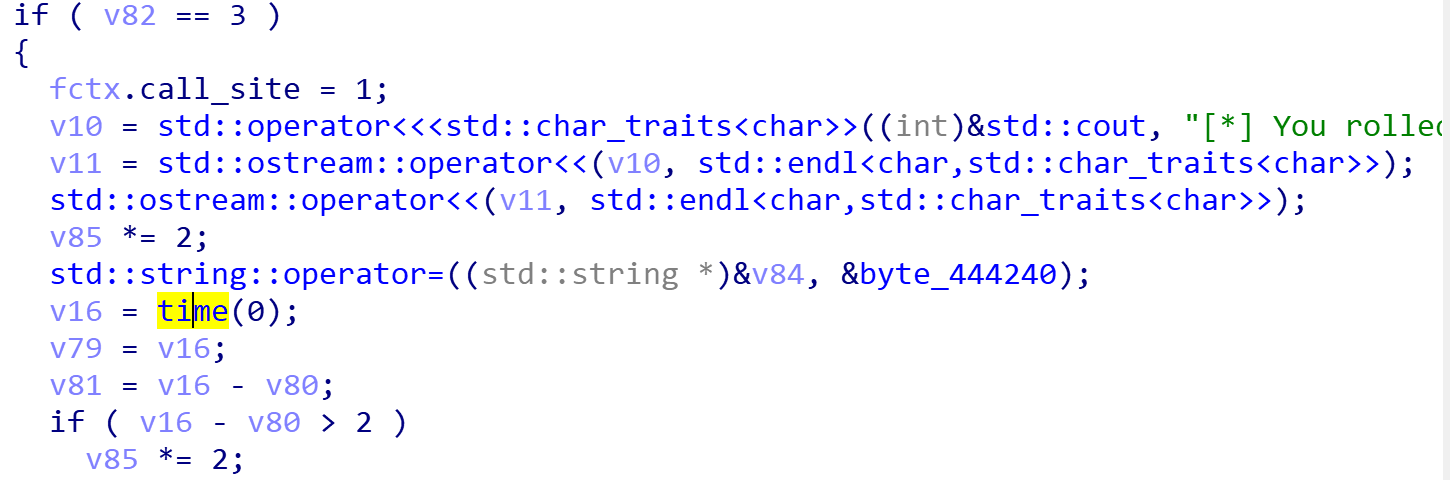
注意这里的time函数,也是反调试用的,比如od调试时time就会比较大,这里可以理解为程序运行时间超过2秒就乘以2
所以这里我们只需要一次v85*=2即可
接着根据31337的五次结果,总结一下所有操作就是
v85=6 *=2 +=4 *=3 +=2 *=2 *=50 /=50 +=65 -=65 *=42 /=42
算出v85=100
最后写出解密代码(还是C好用)
1 | v84 = "132138153D3357472D276A73440526595C79174445771A75497D054A78746A70420271050F2208" |
补充一些,IDA的流程图…….是可以拖动的
举个例子,比如我要把jnz改成jz,以机器码修改的方式
光标处改成8就差不多了,应该是机器码显示的长度(而不是进制,因为我试了15)

网上查一下发现JNZ就是这里的75,而JZ是74
patch一下
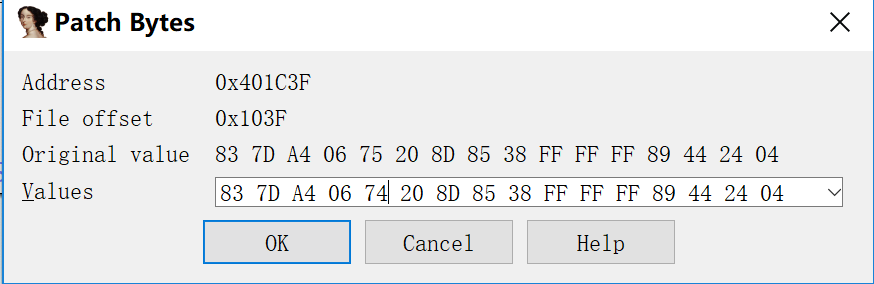
这样1/6的概率就变成5/6了,或者直接改成jmp更好
RE-catalyst
catalyst是催化剂的意思,应该就是让我们nop掉一堆的sleep吧
直接找到关键部分

跟进第一个函数
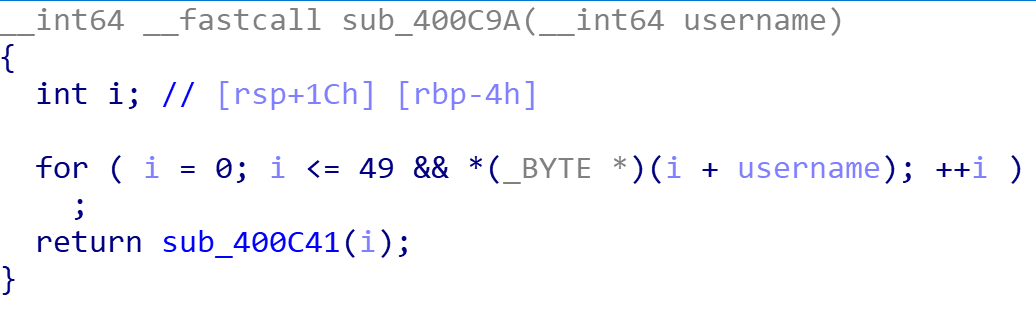

显然这里是对username的长度进行了限制,复制代码,爆破一下
1 |
|
结果是username长度只能是8或12,是第一个限制
4 * (i >> 2) == i 实际表示i是4的倍数,懒得分析了直接爆破吧
进入第二个函数,就是一堆运算
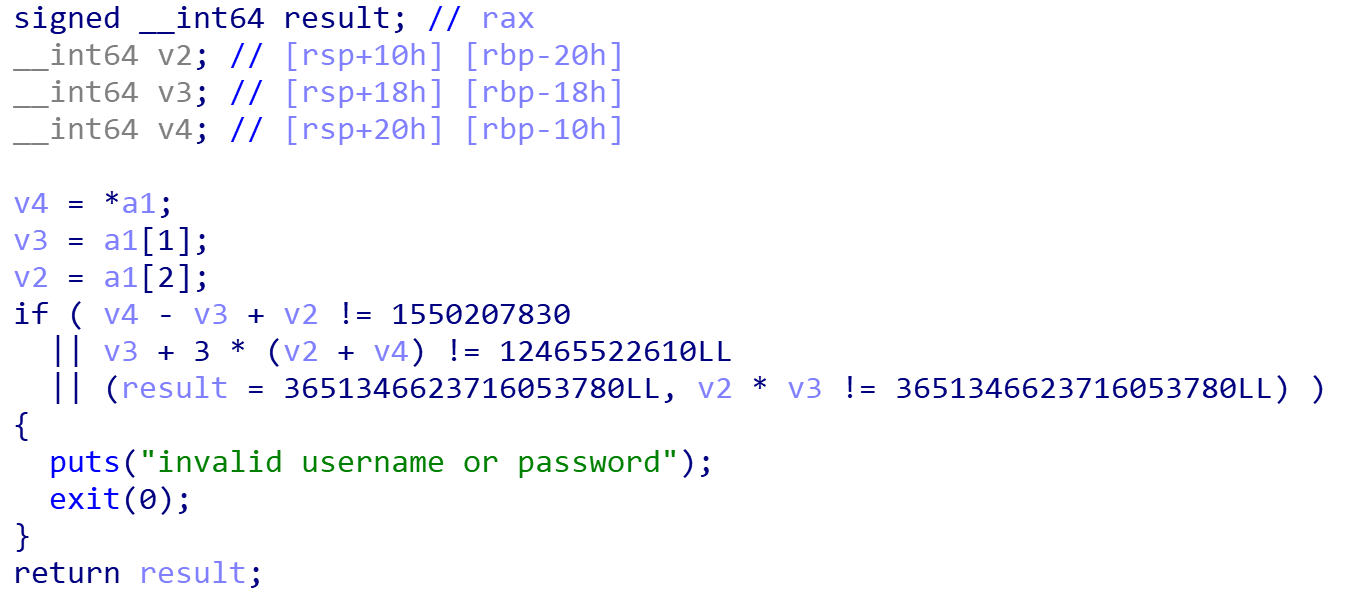
写一个z3的脚本
1 | from z3 import * |
输出结果:
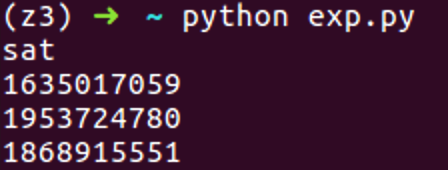
然后把长整型转换成字符串,to_bytes需要py3支持
1 | userin = [1635017059,1953724780,1868915551] |
每四个字节转成一个小端字符,再UTF-8解码
输出: catalyst_ceo
跟进第三个函数,发现没什么影响

继续第四个函数
这个没什么用…
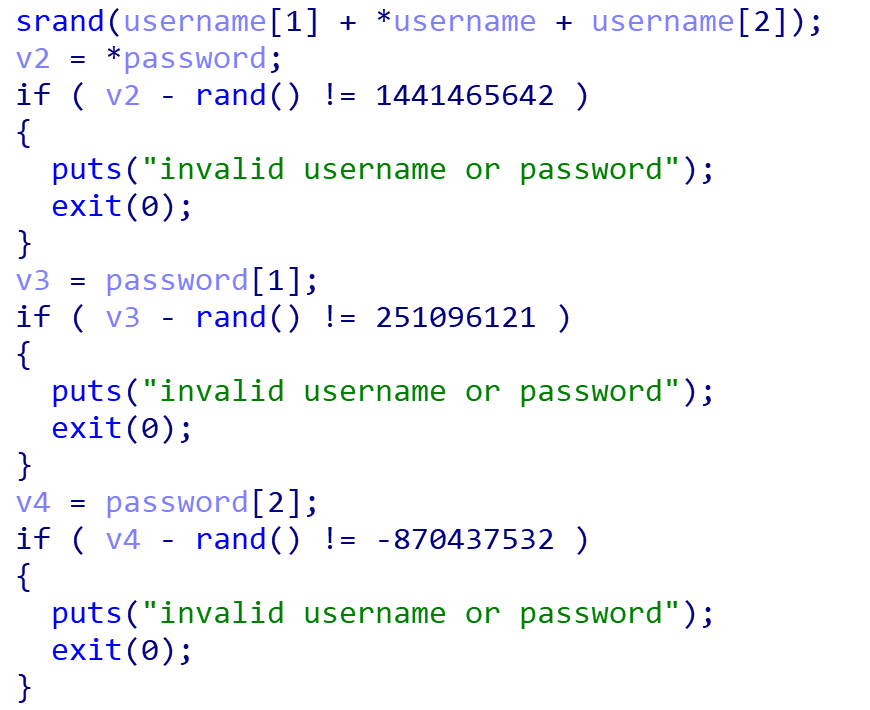
这里主要是随机种子已经定下了,因此我们写另一个程序运行一下就好
第五个函数就是简单的异或
最终的exp:
1 |
|
好多wp说这里a[]要设置成unsigned int,我感觉没道理啊…这里我跑出来没问题
也可以写个程序看看猜测的对不对,这里是因为前面太多sleep,懒得调试
不过以后如果出了问题可以考虑一下有/无符号的问题
我可以清楚地控制C中的每一个bit,为什么要用python呢?
不完全归纳的结论:
int + 32bits,不管后面的32bits是int还是uint,都等于int + 32bits(补),貌似需要加一个前提(32bits)没超过int的上界
也就是说,后面的32bits直接看成int就行了,不需要纠结有无符号